🎯 Objetivos del Proyecto
1️⃣ Rutas principales:
¿Cuáles son las rutas de envío más comunes y sus distancias promedio?
2️⃣ Tiempos de entrega:
¿Qué rutas tienen los tiempos de entrega más largos?
3️⃣ Envíos Top:
¿Cuáles son las fechas de reserva y entrega con mayor actividad?
4️⃣ Análisis de retrasos:
¿Qué factores contribuyen a los retrasos en los envíos?
5️⃣ Información del cliente:
¿Qué clientes reciben la mayoría de los envíos y experimentan retrasos?
6️⃣ Tendencias de los proveedores:
¿Qué proveedores manejan la mayoría de los envíos y algunos tienen mayores retrasos?
7️⃣ Movimiento de materiales:
¿Cuáles son los materiales que se envían con más frecuencia y ciertos materiales tienen tiempos de entrega más largos?
8️⃣ Cuellos de botella:
¿Dónde están los retrasos de envío más comunes según los datos de GPS?
Análisis Exploratorio de Datos (EDA)
Paso 1: Carga y Exploración Inicial de Datos
- Importamos librerías.
- Carga del dataset desde un archivo Excel.
- Exploración inicial.
# Importar librerías
import pandas as pd
import matplotlib.pyplot as plt
from math import radians, sin, cos, sqrt, atan2
# Cargar el archivo Excel
file_path = 'Transportation & Logistics Tracking Dataset_Spanish.xlsx'
df = pd.read_excel(file_path, sheet_name='Datos Primarios')
# Exploración inicial de los datos
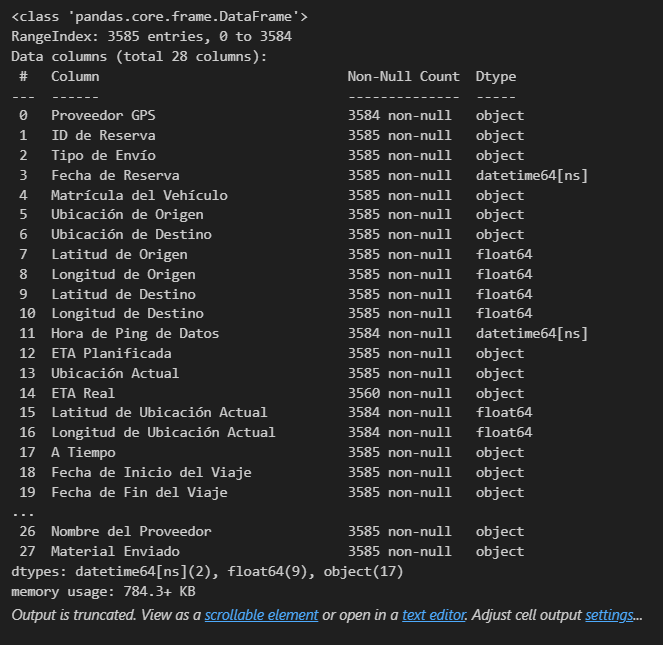
df.head()
df.info()
# Verificar valores nulos, NA y celdas vacías
null_values = df.isnull().sum()
na_values = df.isna().sum()
empty_values = (df == '').sum()
# Mostrar el resumen de valores nulos, NA y celdas vacías
print("Valores nulos por columna:")
print(null_values)
print("\nValores NA por columna:")
print(na_values)
print("\nCeldas vacías por columna:")
print(empty_values)
.sum().PNG)
Paso 2: Transformación de datos
Al detectar campos con datatype incorresctos y valores vacíos como nulos procederé a modificarlos.
# Convertir formatos de fecha
df['ETA Real'] = pd.to_datetime(df['ETA Real'], errors='coerce')
df['ETA Planificada'] = pd.to_datetime(df['ETA Planificada'], errors='coerce')
df['Fecha de Inicio del Viaje'] = pd.to_datetime(df['Fecha de Inicio del Viaje'], errors='coerce')
df['Fecha de Fin del Viaje'] = pd.to_datetime(df['Fecha de Fin del Viaje'], errors='coerce')
#Eliminamos registros sin Proveedor GPS
df = df.dropna(subset=['Proveedor GPS'])
#Cambiamos los valores nulos con la mediana de la columna.
df['Kilómetros Mínimos a Cubrir por Día'] = df['Kilómetros Mínimos a Cubrir por Día'].fillna(df['Kilómetros Mínimos a Cubrir por Día'].median())
#Cambiamos los valores nulos con la moda de la columna.
df['ETA Real'] = df['ETA Real'].fillna(df['ETA Real'].mode()[0])
#Cambiamos los valores nulos con la cadena 'Falta Información'
df['Tipo de Vehículo'] = df['Tipo de Vehículo'].fillna('Falta Información')
#Cambiamos los valores nulos con la cadena 'Falta Información'
df['Nombre del Conductor'] = df['Nombre del Conductor'].fillna('Falta Información')
#Cambiamos los valores nulos con la cadena 'Falta Información'
df['Número de Móvil del Conductor'] = df['Número de Móvil del Conductor'].fillna('Falta Información')
# Segunda verificación de valores nulos, NA y celdas vacías
null_values = df.isnull().sum()
na_values = df.isna().sum()
empty_values = (df == '').sum()
# Mostrar el resumen de valores nulos, NA y celdas vacías
print("Valores nulos por columna:")
print(null_values)
print("\nValores NA por columna:")
print(na_values)
print("\nCeldas vacías por columna:")
print(empty_values)
.sum() resultado.PNG)
# Exportamos el DataFrame limpio a un archivo Excel
df.to_excel('db_Transportation_&_Logistics_Tracking.xlsx', index=False, sheet_name='Datos Limpios')
print("Archivo exportado exitosamente como 'db_Transportation_&_Logistics_Tracking.xlsx'")
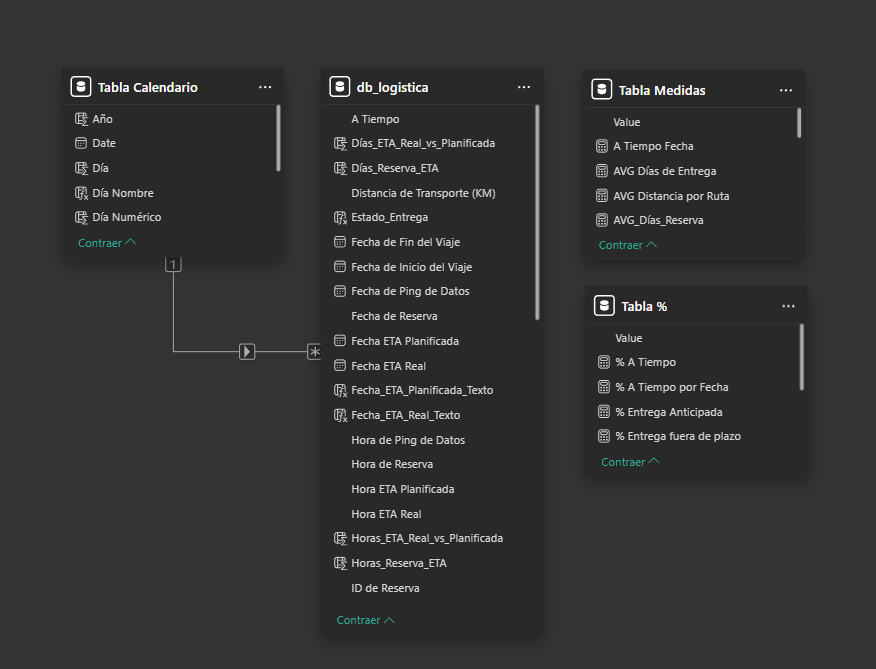
Tabla Calendario, Medidas y Fórmulas DAX
1. Creación de la Tabla Calendario
Para facilitar el análisis temporal, creé una tabla de calendario (Tabla Calendario) que contiene fechas iterativas basadas en el rango de fechas de la tabla db_logistica. Luego, agregué columnas adicionales para desglosar la fecha en componentes útiles como día, mes, año, semestre y semana.
Tabla Calendario = CALENDAR(
MIN(db_logistica[Fecha de Reserva]),
MAX(db_logistica[Fecha de Reserva]))
Columnas adicionales:
Año = YEAR('Tabla Calendario'[Date])
Mes = MONTH('Tabla Calendario'[Date])
Día = DAY('Tabla Calendario'[Date])
Mes Nombre = FORMAT('Tabla Calendario'[Date], "mmmm")
Día Nombre = FORMAT('Tabla Calendario'[Date], "dddd")
Semestre = IF(MONTH([Date]) <= 6, 1, 2)
Día Numérico = WEEKDAY('Tabla Calendario'[Date], 2)
2. Creación de Medidas para db_logistica
Creé una tabla de medidas (Tabla Medidas) para calcular métricas claves relacionadas con las Reservas, Transporte y Niveles de Servicio.
Total ID Reserva = COUNT(db_logistica[ID de Reserva])
Total Market = CALCULATE(
COUNTROWS(db_logistica),
db_logistica[Tipo de Envío] = "Market")
Total Regular = CALCULATE(
COUNTROWS(db_logistica),
db_logistica[Tipo de Envío] = "Regular")
SUM Distancia de Transporte (KM) = SUM(db_logistica[Distancia de Transporte (KM)])
Entrega Anticipada = CALCULATE(
COUNTROWS(db_logistica), db_logistica[Estado_Entrega] = "Entrega Anticipada")
Entrega Mismo Día = CALCULATE(
COUNTROWS(db_logistica), db_logistica[Estado_Entrega]="Entrega mismo día")
Entrega Fuera de Plazo = CALCULATE(
COUNTROWS(db_logistica), db_logistica[Estado_Entrega] = "Entrega fuera de plazo")
AVG Días de Entrega = AVERAGE(db_logistica[Días_ETA_Real_vs_Planificada])
AVG Distancia por Ruta =
AVERAGEX(
db_logistica,
db_logistica[Distancia de Transporte (KM)])
AVG_Días_Reserva =
AVERAGE(db_logistica[Días_Reserva_ETA])
AVG_Envios_Dias =
AVERAGEX(
db_logistica,
DATEDIFF(
db_logistica[Fecha de Reserva] + db_logistica[Hora de Reserva],
db_logistica[Fecha ETA Real] + db_logistica[Hora ETA Real],
DAY
)
)
Tiempo de Entrega desde Reserva =
VAR Diferencia = DATEDIFF( db_logistica[Fecha de Reserva] + db_logistica[Hora de Reserva],
db_logistica[Fecha ETA Real] + db_logistica[Hora ETA Real], SECOND)
VAR Dias = QUOTIENT(Diferencia, 86400) // 86400 segundos en un día
VAR Horas = QUOTIENT( MOD(Diferencia, 86400), 3600 ) // 3600 segundos en una hora
VAR Minutos = QUOTIENT( MOD(Diferencia, 3600), 60 ) // 60 segundos en un minuto
RETURN
FORMAT(Dias, "0") & " días, " & FORMAT(Horas, "0") & " horas, " & FORMAT(Minutos, "0") & " minutos"
Estado_Entrega =
VAR FechaPlanificada = db_logistica[Fecha ETA Planificada]
VAR FechaETAReal = db_logistica[Fecha ETA Real]
RETURN
IF(
FechaETAReal = FechaPlanificada,
"Entrega mismo día",
IF(
FechaETAReal > FechaPlanificada,
"Entrega fuera de plazo",
"Entrega Anticipada"
)
)
Rango_Horas_ETA_Real =
" " & FORMAT(TIME(HOUR(db_logistica[Hora ETA Real]), 0, 0), "hh:mm") & " - " &
FORMAT(TIME(HOUR(db_logistica[Hora ETA Real]) + 1, 0, 0), "hh:mm")
3. Creación de Medidas para Porcentajes
Para complementar el análisis, creé una segunda tabla de medidas (Tabla %) que calcula porcentajes basados en las métricas anteriores. Esto permite entender la proporción de Reservas en cada estado respecto al total.
% Total Regular = DIVIDE([Total Regular],[Total ID Reserva])
% Total Market = DIVIDE([Total Market], [Total ID Reserva])
% Entrega mismo día = DIVIDE([Entrega Mismo Día],[Total ID Reserva])
% Entrega fuera de plazo = DIVIDE([Entrega Fuera de Plazo],[Total ID Reserva])
% Entrega Anticipada = DIVIDE([Entrega Anticipada],[Total ID Reserva])
Conclusiones del Proyecto
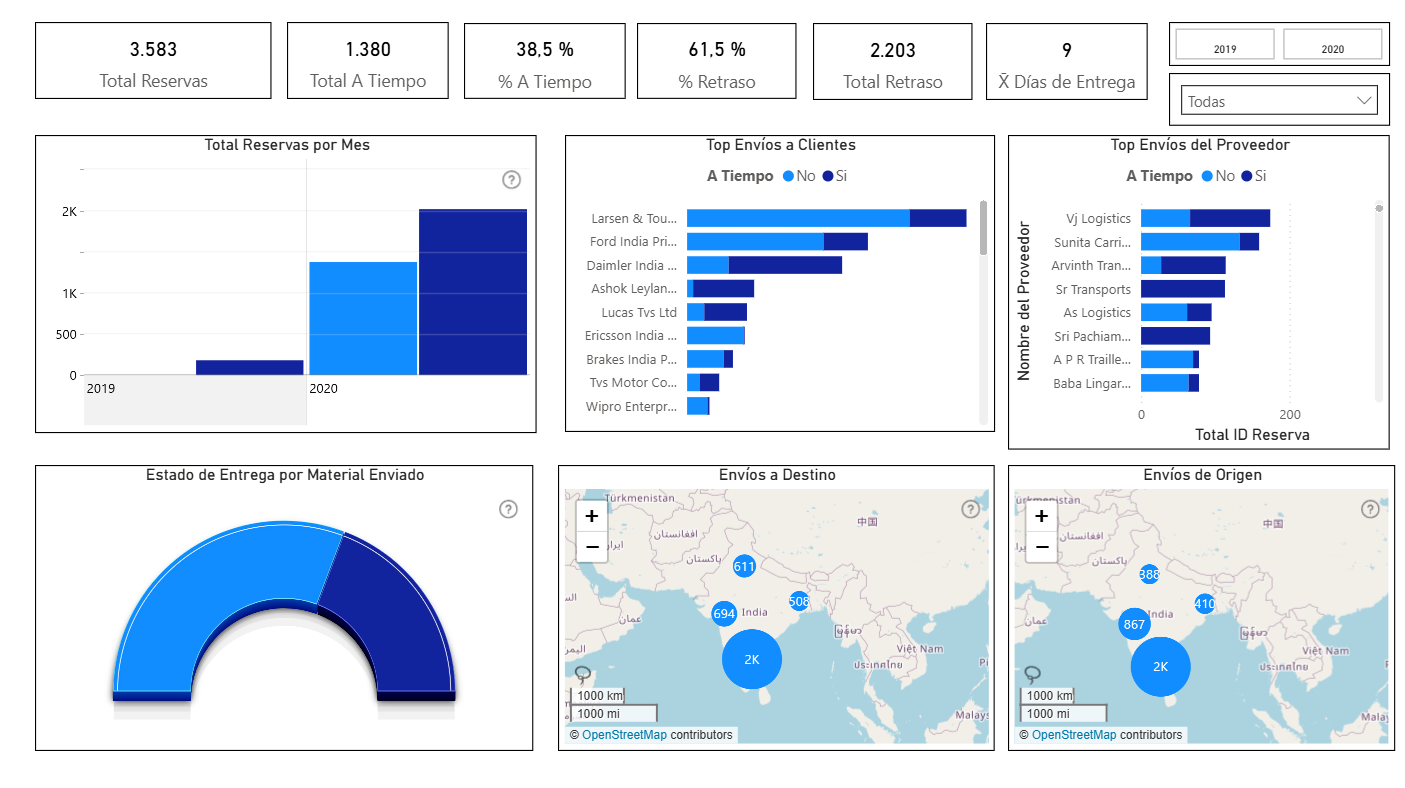
Panel 1: Análisis de Reservas
- Análisis de Reservas: El modelo de datos revela que las Reservas Regulares constituyen la mayoría con 3.525 ordenes, frente a 58 Reservas Market. Esto demuestra la importancia de los clientes Regulares como base del negocio.
- Análisis de Comportamiento: Se identificaron picos de solicitudes en años y meses específicos como lo fué el año 2020 con 3.401 Reservas frente a 182 Reservas del año 2019, y en los meses del año 2020 entre junio y agosto se aprecian los pick mas altos (Junio: 496, Julio: 942, Agosto: 1.432).
- Estado de Entregas: Más del 61% de las solicitudes de las Reservas u ordenes fueron entregadas fuera de plazo según su planificación, mostrando un deficit operativo. Sin embargo, el 38.52% de las Reservas fueron entregadas a tiempo según planificación, lo que sugiere opciones de mejora.
- Crecimiento de Solicitudes por Año: Según las cantidades de reservas por año podemos decir que:
- De 2019 a 2020: Hubo un incremento de 3.401 solicitudes equivalente a un crecimiento del 1.768%.
Este crecimiento refleja una expansión operativa y una mayor demanda de los servicios ofrecidos.
El análisis de reservas revela una evolución significativa en la cantidad de solicitudes, con un crecimiento exponencial del 1.768% de 2019 a 2020.
Este incremento refleja una mayor demanda y expansión operativa, pero también destaca la importancia de optimizar los procesos logísticos para garantizar
que este crecimiento sea sostenible. La gran mayoría de las reservas provienen de clientes regulares, lo que subraya la necesidad de fidelizar a este segmento
y garantizar que su experiencia sea eficiente y confiable. Sin embargo, un punto crítico identificado es el cumplimiento en los tiempos de entrega, ya que más
del 61% de las reservas se entregaron fuera de plazo. Esto indica un déficit operativo que podría afectar la percepción del servicio y la retención
de clientes a largo plazo.
Recomendaciones:
- Implementar herramientas de pronóstico de demanda para anticipar necesidades logísticas y distribuir mejor los recursos.
- Optimizar la asignación de vehículos y conductores para equilibrar la carga de trabajo y reducir tiempos de espera.
- Mejorar la planificación de entregas, ajustando los tiempos de preparación y salida para minimizar retrasos.
- Establecer un margen de tiempo adicional en la planificación para contingencias, como condiciones climáticas adversas o problemas mecánicos.
- Utilizar software de gestión de órdenes que permita automatizar la asignación de recursos y mejorando la eficiencia en la coordinación de recursos y planificación de entrega.
- Incorporar herramientas de inteligencia artificial para predecir picos de demanda en función de temporadas, eventos o tendencias históricas, y ajustar la capacidad operativa en consecuencia.
- Implementar un sistema de notificaciones en tiempo real para informar a los clientes sobre el estado de sus reservas, incluyendo posibles retrasos y soluciones alternativas.
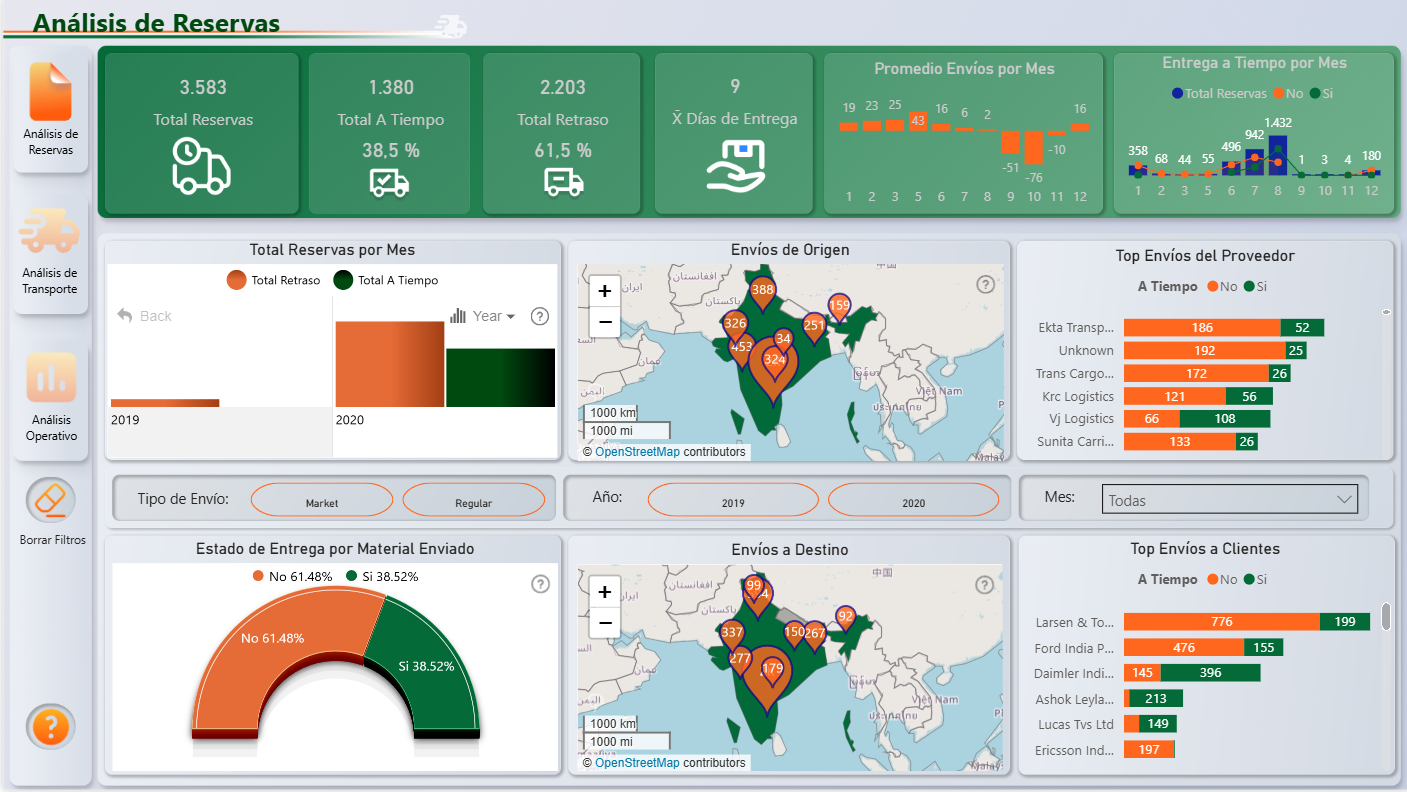
Panel 2: Análisis de Transporte
- 2019
- Cantidad de Camiones: Se utilizaron 146 camiones para entregar 182 órdenes de entrega.
- Estado de Entrega: De las 182 ordenes, el 100% fué entregada fuera de plazo según planificación.
- Rutas con mayor kilometraje: Ruta de origen: Mumbai. Destino: Bangalore. Distancia: 3.157 KM, y se utilizaron 3 camiones de 20 pies.
- Rutas con mayores Retrasos: WestBengal, Odisha y Delhi son los estados que presentan los mayores retrasos de entrega.
- Kilometros mínimos a recorrer por camión (250 KM): Hubo un promedio total de 170 KM, lo que nos dice que los camiones recorrieron menos kilometros según lo establecido por la empresa.
- Días y Horarios con Mayores RetrasosSe aprecia que los días Lunes y Jueves presentan los mayores retrasos entre las 01:00 y 02:00 AM.
- Tipo de Vehiculos con Mayores RetrasosPodemos ver que los camiones de 40 pies semi remolques tienen las mayores solicitudes de reservas de entrega con retrasos.
- 2020
- Cantidad de Camiones: Se utilizaron 1.188 camiones para entregar 3.401 órdenes de entrega.
- Estado de Entrega: De las 3.401 ordenes, el 33% fué entregada a tiempo, 11% al límite de la fecha de entrega y un 56% fuera de plazo según planificación.
- Rutas con mayor kilometraje: Ruta de origen: Gurgaon. Destino: Kanchipuram. Distancia: 391.950 KM, y se utilizaron 89 camiones de 32 pies.
- Rutas con mayores Retrasos: TamilNadu, Haryana y Maharashtra son los estados que presentan los mayores retrasos de entrega.
- Kilometros mínimos a recorrer por camión (250 KM): Hubo un promedio total de 887 KM, lo que nos dice que los camiones recorrieron más kilometros según lo establecido por la empresa.
- Días y Horarios con Mayores RetrasosSe aprecia que los días Lunes, martes y Jueves presentan los mayores retrasos de entrega entre las 11:00 y 18:00 PM.
- Tipo de Vehiculos con Mayores RetrasosPodemos ver que los camiones de 32 Y 40 pies tienen las mayores solicitudes de entrega con retrasos.
El análisis del transporte muestra un aumento significativo en la utilización de camiones, pasando de 146 en 2019 a 1.188 en 2020, en respuesta al crecimiento de la demanda. No obstante, la eficiencia
operativa aún presenta desafíos, ya que en 2019 el 100% de las entregas fueron fuera de plazo, y aunque en 2020 hubo una mejora relativa con un 33% de entregas puntuales, el 56% aún sufrió retrasos.
Esto refleja la necesidad de optimizar las rutas y mejorar la planificación de la flota para garantizar una distribución más eficiente. Además, se evidenció que los camiones de 32 y 40 pies tienden a
presentar más retrasos, lo que sugiere que es necesario evaluar si el tipo de vehículo utilizado es el más adecuado para ciertas rutas. También se identificaron horarios críticos de retraso, especialmente los
lunes, martes y jueves en franjas horarias específicas, lo que permite replantear la programación de despachos para evitar congestionamientos.
Recomendaciones:
- Implementar tecnología de monitoreo en tiempo real de los encargos, como TMS, SAAS, etc.
- Utilizar software de optimización de rutas que considere factores como el tráfico, las condiciones de las carreteras y la distancia para reducir tiempos de entrega y costos de combustible.
- Realizar un análisis de la capacidad de carga de los camiones para evitar subutilización o sobrecarga. Por ejemplo, evaluar si los camiones de 32 y 40 pies son los más adecuados para ciertas rutas.
- Ajustar la programación de despachos en días y horarios críticos para reducir el impacto de la congestión.
- Evaluar vehículos más adecuados para ciertas rutas, especialmente donde los camiones más grandes presentan demoras.
- Establecer rutas fijas para ciertos destinos frecuentes y asignar conductores especializados en rutas críticas o de mayor valor.
- Implementar un sistema de mantenimiento preventivo para reducir fallas mecánicas que puedan causar retrasos.
- Reasignar camiones y conductores según la demanda geográfica, priorizando áreas con mayores retrasos o mayor volumen de entregas.
- Considerar el uso de vehículos más pequeños para entregas locales o en áreas urbanas congestionadas.
- Establecer incentivos para conductores que cumplan con los plazos de entrega y mantengan un buen desempeño operativo.
Panel 3: Análisis Operativo
- Retrasos en Conductores: Se identificó una alta tasa de retrasos en la entrega, donde algunos conductores presentan más del 70 % de sus entregas fuera de plazo. No obstante, un grupo reducido ha demostrado mayor eficiencia, lo que sugiere diferencias en el desempeño operativo.
- Materiales con Mayores Retrasos: Se detectaron fallos en la planificación de inventario y distribución, reflejados en los siguientes materiales con altos índices de retraso en la entrega:
- Spindle Assy: 76 % de retraso.
- Wiper Motor Link: 71 % de retraso.
- Ball Bearing: 68 % de retraso.
- Materiales con Mejor Cumplimiento: Algunos materiales lograron un mejor desempeño en términos de puntualidad de entrega:
- Solenoid Assy: 35 % de entregas a tiempo.
- Empty Foam: 31 % de entregas a tiempo.
- Falta de Datos en Entregas: Se detectó que en múltiples casos no se cuenta con información completa sobre la puntualidad de las entregas. Esta falta de datos afecta la precisión del análisis y dificulta la identificación de problemas específicos.
El análisis operativo revela que la eficiencia en la entrega sigue siendo un desafío crítico, con un alto porcentaje de retrasos en algunos conductores y ciertos materiales mostrando un desempeño deficiente. La falta de datos sobre puntualidad en muchas entregas dificulta una evaluación precisa de la operación y limita la capacidad de aplicar mejoras efectivas.
Recomendaciones:
- Establecer acuerdos con proveedores para garantizar la disponibilidad de materiales críticos, como el Spindle Assy y el Wiper Motor Link.
- Realizar un análisis detallado de los motivos detrás de los retrasos en los materiales más problemáticos, identificando si se deben a problemas de proveedores, almacenamiento o transporte.
- Establecer un sistema de evaluación de desempeño para conductores y personal operativo, con incentivos para aquellos que cumplan o superen los objetivos de entrega.
- Realizar revisiones periódicas del desempeño del personal a cargo dfe la planificación como conductores y proporcionar retroalimentación constructiva
- Trabajar en estrecha colaboración con los proveedores para mejorar la puntualidad en la entrega de materiales y reducir los cuellos de botella en la cadena de suministro.
- Desarrollar planes de contingencia para situaciones imprevistas, como huelgas, desastres naturales, calles cortadas y en mal estado o problemas técnicos, que puedan afectar la operación.